
喜报:EAGLE实验室多篇论文被顶级国际期刊和会议录用
近期,EAGLE实验室周晟老师和博士生谷春斌、张震的学术论文分别被国际会议International Conference on Computer Vision(ICCV)2021、ACM multimedia(ACM MM)2021、国际期刊IEEE Transactions on Knowledge and Data Engineering(TKDE)录用。
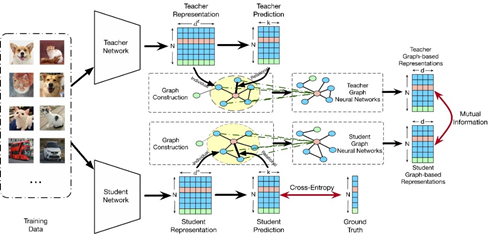
周晟老师的论文《Distilling Holistic Knowledge with Graph Neural Networks》被计算机视觉领域公认的顶级国际会议ICCV 2021录用为全文。
知识蒸馏作为一种模型压缩的重要技术,它通过从参数较多,效果较好的教师模型中蒸馏知识,来训练参数较少的学生模型,以提升学生网络在资源有限的设备上的性能。现有的知识蒸馏方法主要考虑两种类型的知识,即个体知识和关系知识。然而这两种知识通常以独立的方式进行建模,两种知识之间的关系则被忽略,这使得学生模型在训练时难以获得足够的知识。好的学生模型需要融合个体知识和关系知识,并保留两种信息之间的相关性。在本文中,我们提出基于实例间的属性图来从教师网络中提取整体知识。通过图神经网络从相关邻域样本中聚合个体知识,将整体知识表示为统一的基于图嵌入向量,并利用对比学习的方法来指导学生模型的训练。本文在大量数据集上进行了性能实验和消融实验,实验结果验证了方法的有效性。
博士生谷春斌的论文《Image Search with Text Feedback by Deep Hierarchical Attention Mutual Information Maximization》被多媒体研究领域公认的顶级国际会议ACM MM 2021录用为长文。
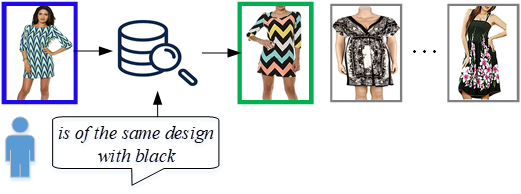
由于多模态数据的快速增长,跨模态检索受到了研究者的广泛关注,其任务是将一种或多种模态的数据作为查询条件检索其他模态的数据。本文聚焦的是一种特殊的跨模态检索任务,即基于文本反馈的图像检索。具体讲,此任务通过参考图像及对其特性进行更改的描述检索目标图像,如下图所示。
本质上讲,跨模态检索是将不同模态数据映射到相同表征空间中并利用度量学习算法度量不同模态之间的相似性。这种思想是简单且易实现的。但是我们发现,不同模态数据存在分布差异,直接利用其表征进行相似性度量会影响最终检索精度。本文聚焦的检索任务中,包含文本、图像及文本与图像的融合三种模态,我们利用两种类型的互信息最大化实现他们的分布对齐。本文首先使用基于注意力机制的互信息最大化将文本与图像映射到同一子空间中;进一步,我们利用层次化互信息最大化实现图像表征与融合表征的分布对齐;最终,我们在不同模态的共同子空间中实现图像检索。我们的模型框架如下图所示。

实际上,本文提出的利用基于注意力层次化互信息最大化消除模态差异的模型对于大多数跨模态检索任务都具有较好的适用性。
博士生张震的论文《Hierarchical Multi-View Graph Pooling with Structure Learning》被数据挖掘研究领域公认的顶级国际期刊TKDE录用为全文。
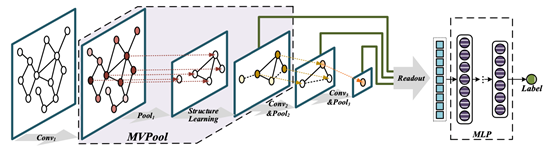
图(graph)也称为网络(network)是一种用点和边来建模实体与实体之间关系的常用数据结构,它广泛的存在于现实场景中,例如社交网络、论文引用网络、道路网络等等。挖掘海量图数据中的语义信息有着重大的应用价值。现有的研究方法大多尝试设计有效的图卷积操作来进行图数据的表征学习,忽略了池化操作的重要性。我们发现设计有效的池化算子不仅可以降低图神经网络模型的时间复杂度,还可以捕获到图数据中的层级结构信息。因此,本文尝试利用多视图中的上下文信息去综合衡量每个节点的重要性来进行池化操作,同时我们还发现经过池化操作之后会丢失一部分图结构信息,所以本文又创新性的提出了结构学习模块来对图结构进行微调。本文所提出的算法是一个通用的模块,它可以适用于大部分现有图神经网络模型。我们在13个公开数据集上验证了模型的有效性,包括5个节点分类数据集和8个图分类数据集,并与20多个现有方法进行了对比,均取得了不同程度的提升。模型框架图如图所示,论文全文地址:https://ieeexplore.ieee.org/abstract/document/9460814, 实验数据以及代码请访问:https://github.com/cszhangzhen/MVPool

高质量论文多次被ICCV、ACM MM、TKDE录用说明了实验室在模型压缩和轻量级模型训练部署、多模态、数据挖掘领域奠定了一定的研究基础,充分显示了在高水平国际会议上连续发表论文的能力。