实验室博士生潘正新的论文“Hubness Reduction with Dual Bank Sinkhorn Normalization for Cross-Modal Retrieval”、博士生卢杰龙的论文“Where Views Meet Curves: Virtual Anchors for Hyperbolic Multi-View Graph Diffusion”、博士生史可越的论文“LUMOS: A Lumbar Multimodal Osteoporosis Screening Dataset with X-ray and CT images”硕士生陈威志的论文"PG-Agent: An Agent Powered by Page Graph"被MM 2025录用。

ACM International Conference on Multimedia (ACM MM) 是多媒体领域的国际顶级会议,由美国计算机学会(ACM)主办,自1993年首次举办以来,已成为该领域学术界和工业界交流的重要平台。该会议被中国计算机学会(CCF)列为计算机图形学与多媒体领域的A类会议,并且在多媒体领域具有极高的影响。

高维空间的表征学习普遍存在枢纽问题。研究表明,深度学习模型的表征会趋向于分布在超球面的薄壳上,导致距离度量失去判别性。在这种几何特性下,少数样本会因其特殊的空间位置而频繁出现在其他样本的近邻列表中,形成所谓的"枢纽点",而大部分样本则沦为"反枢纽点",几乎不会被检索到。这种枢纽效应导致当前多模态检索结果退化。
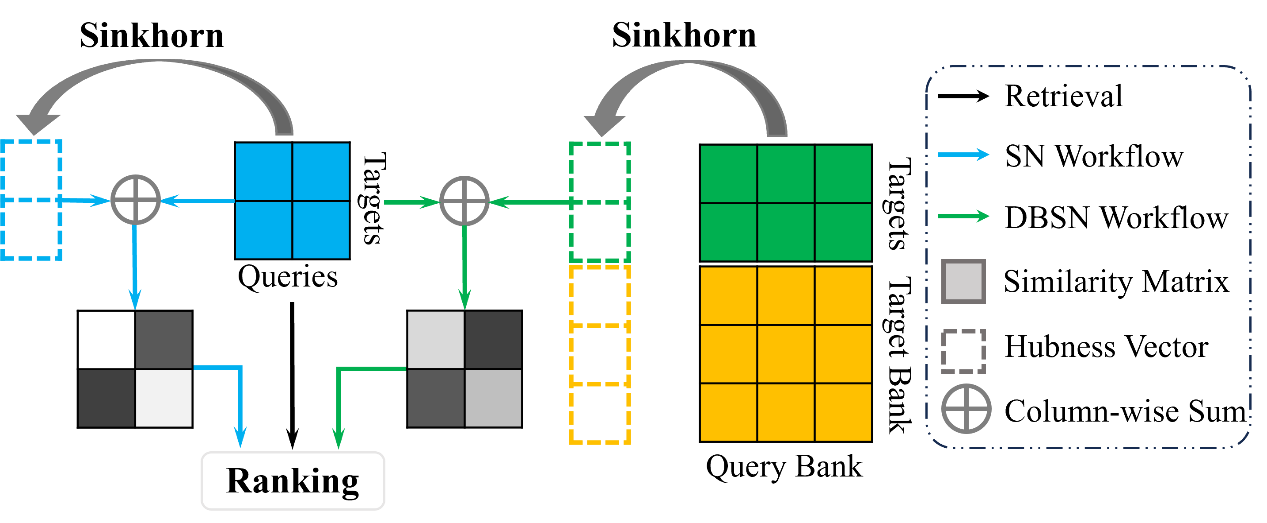
此前方法启发式使用Inverted Softmax(IS)方法解决枢纽问题,针对待检索目标进行归一化,发现能显著提升检索结果。然而,此前方法并未科学地分析其有效原理。处于此局限,我们建立一套概率均衡框架解释IS。我们揭示IS本质是对待检索目标进行概率均衡,让每个目标被检索概率一致,从而缓解枢纽问题。但是,仅考虑目标概率均衡是次优的。为此,我们对查询也做出概率均衡的约束,提出Sinkhorn Normalizarion(SN)算法,实现查询-目标双均衡。SN算法相较于IS进一步提升检索结果,验证了其在query-aware场景下的有效性。更进一步,考虑SN方法在更接近现实的query-agnostic场景下的退化,我们构造额外的查询库与目标库,提出Bank Sinkhorn Normalization(DBSN)算法,扩充SN算法。DBSN有效地解决了SN在query-agnostic场景下的退化问题。SN算法与DBSN算法的示意图如下:
图 1 (a) SN算法直接利用测试查询估计枢纽性向量;(b) DBSN通过引入查询库和目标库来降低分布差异,从而提升枢纽性估计的准确性。
我们在图文检索、文本视频检索、文本语音检索、以图搜图、图像分类等诸多任务的不同benchmarks上开展实验,证实SN算法与DBSN算法的有效性。
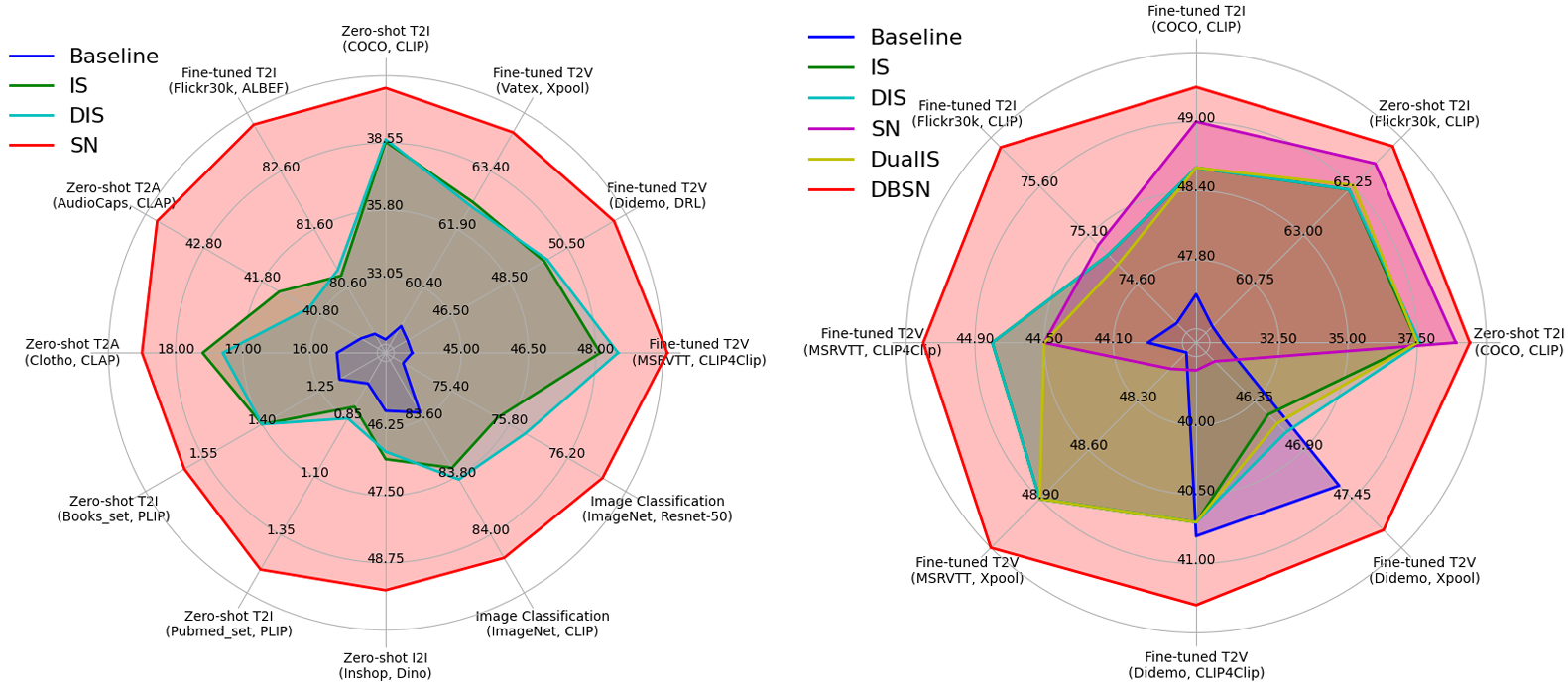
图 2 左图:在query-aware场景(直接将测试集的查询作为查询库)下SN方法与现有方法的对比;右图:在query-agnostic场景(使用训练集的查询作为查询库)下DBSN方法与现有方法的对比。
相关方法细节与实验设置及结果请参考我们的论文原文。我们的论文将公开于预印本网站arxiv上, 模型代码将在Github仓库https://github.com/ppanzx/DBSN上公开。

随着多源异构数据在多模态分析、生物信息学与推荐系统等领域的广泛应用,如何充分挖掘其内部关联与结构信息成为研究的核心问题之一。
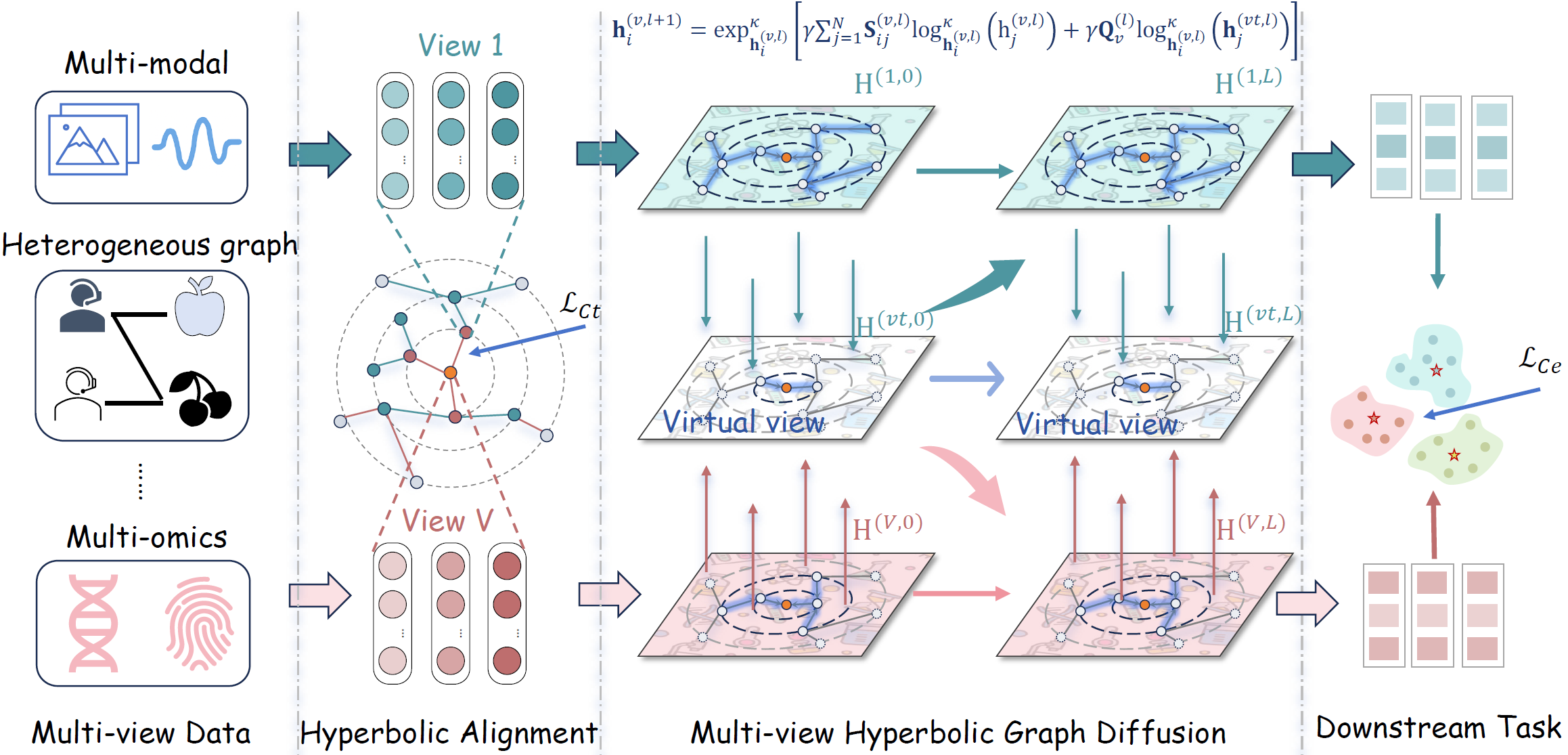
多源数据常来自不同模态(如图像、文本、基因表达等),具有非统一的语义结构、尺度分布与几何特性,导致在统一的表示空间中学习具有挑战性。尤其是传统的欧氏空间在面对多源数据所呈现出的层次结构时,往往面临嵌入扭曲与跨视图信息交互不足等问题,限制了模型对全局关系与语义对齐的建模能力。为解决上述问题,我们提出了一种的多源异构图学习框架 ViHMGD,通过将每个数据源嵌入到低维超曲空间以保持其内在结构,并引入可学习的虚拟视图作为跨源锚点,引导多源数据之间的信息扩散与几何对齐。该框架基于连续时间超曲热扩散机制,不仅保留了局部结构的平滑性,同时促进了全局语义的一致性,显著提升了在复杂多源任务中的建模能力。实验结果表明,ViHMGD在多个公开多元异构数据集上都能达到相当或超越当前的基线模型的效果。

骨质疏松症作为影响超 2 亿人的全球公共卫生难题,早期筛查依赖骨密度(BMD)检测,而双能 X 射线吸收法(DXA)虽为 “金标准”,却因成本高、辐射风险、设备普及率低,难以覆盖大规模人群筛查。近年来,深度学习技术为通过 X 射线、CT 等常规影像预测 BMD 提供了新路径,但现有公开数据资源存在多模态数据缺失、标注质量不足、临床关联性弱等短板,严重制约研究进展。
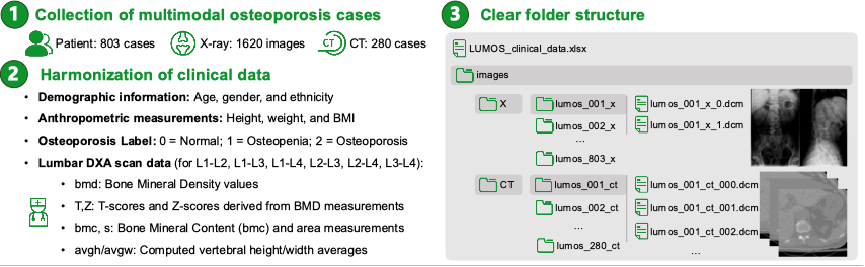
为弥补该领域多模态配对数据的空白,团队提出了一个腰椎多模态骨质酥松症筛查数据集(LUMOS),收集数据涵盖 803 名亚洲患者,包括1620 张腰椎 X 射线影像(含正位、侧位双视角)、280 组配对腰椎 CT 扫描数据,以及全部患者的 DXA 实测指标,包含 L1-L4 节段的 BMD 值、T 分数、Z 分数,还记录了骨矿物质含量、椎体面积等细化数据。所有影像模态的时间间隔小于6 个月,确保数据在临床时间维度上的关联性,为跨模态建模提供可靠基础。团队对数据集人口结构与疾病分布进行分析,年龄集中于 60-69 岁与 70-79 岁、女性占比 80.7% 且骨质疏松患病率更高等结果高度契合亚洲人群流行病学特征,相关性分析也验证数据特征与临床认知一致,为骨质疏松 AI 研究提供了高质量、高临床适配性的多模态数据支撑。
 .
.
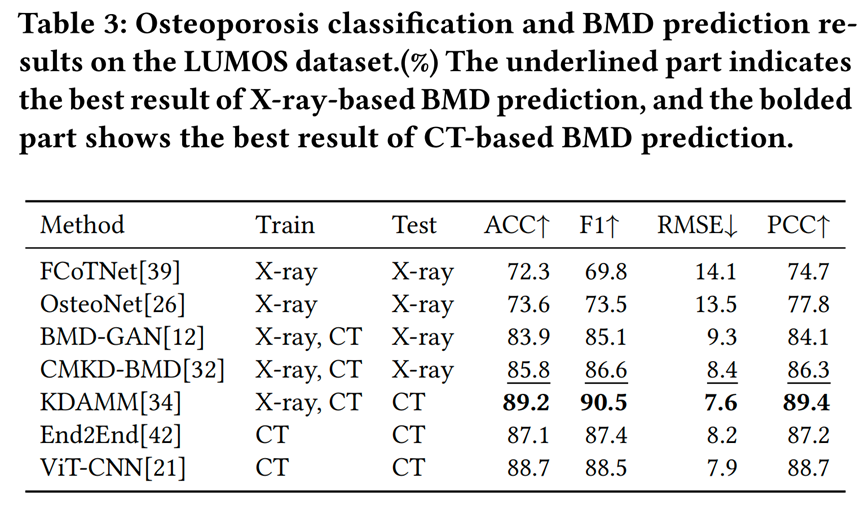
LUMOS 数据集的多模态特性可以支撑骨质疏松症分类、BMD 预测、医学影像分割、医学影像合成等任务。基于 LUMOS 的骨质疏松症分与BMD 预测测试结果显示,多模态模型性能显著优于单模态,验证了数据集对提升模型精度的支撑作用。

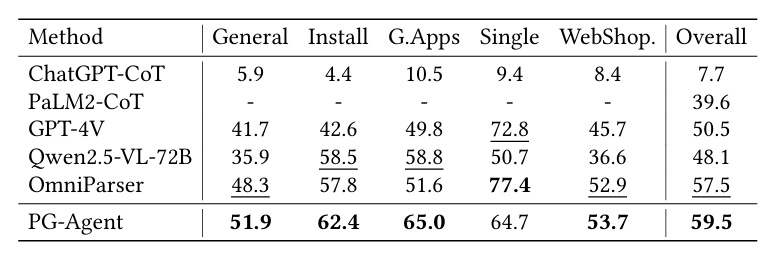
GUI agent作为对GUI界面进行自动化操作的智能代理,既能够方便普通人群的日常设备使用,也可以作为无障碍助手减小特殊群体使用手机的难度。为了让GUI agent能够完成人类的任务,现有的做法通常是根据设计的一系列任务,采集人类的真实操作轨迹来让GUI agent学习软件的使用方式,这一类轨迹数据通常是连续的链式操作。然而,随着应用软件越来越复杂,GUI agent对软件的认知要求也越来越高,而采集的每条链式数据都只能反映软件的一小部分,难以充分地反映软件整体的页面跳转关系。当正在代理的任务和轨迹采集时的任务不完全一致时,GUI agent就很难利用以往学习的轨迹知识。
为了解决这一问题,本研究提出了一个自动化的页面图谱构建方案,利用轨迹之间的交集页面作为锚点,将现有的离散轨迹重新构建成了一个统一的页面图谱,而每一个潜在的线性轨迹本质上是在页面图谱上的一次路径采样。这样一来只需要一个页面图谱,就能直观反映所有页面之间的跳转关系,不再需要从离散的轨迹之间拼凑导航信息。
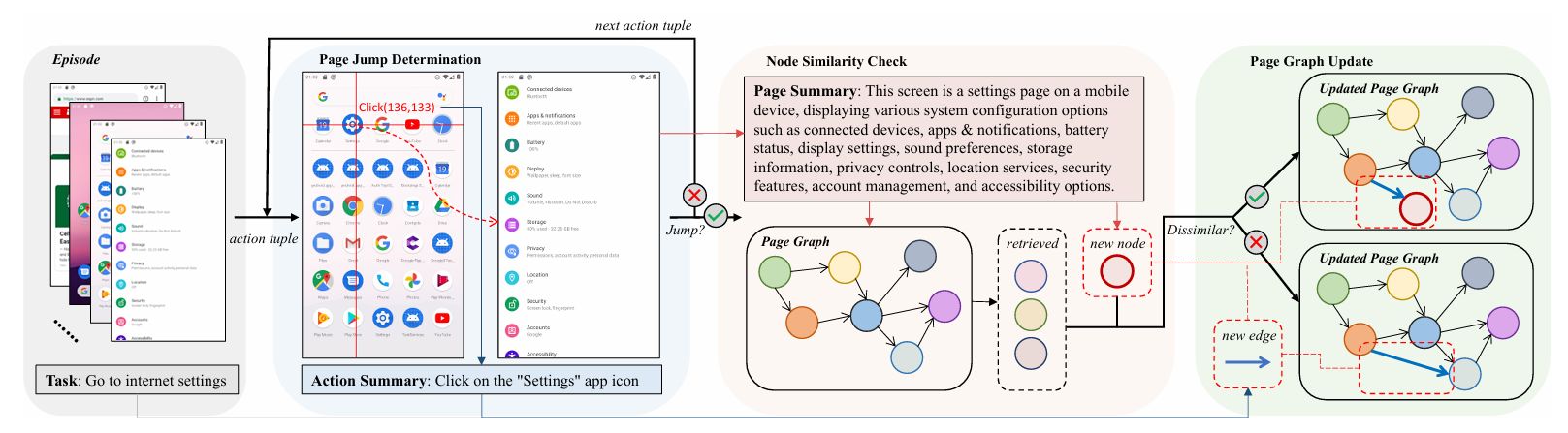
在执行阶段,每次来到一个新的页面,agent会基于当前页面的信息摘要从页面图谱定位一个节点,后通过BFS获取若干跳内的页面跳转情况,以RAG形式生成说明书来帮助agent了解当前正在操作的软件。为了深度利用召回的信息,本研究进一步引入了Multi-Agent集群,分为总规划agent,子任务agent以及决策agent,其中召回的说明书作为可靠的先验知识注入子任务agent和决策agent,帮助其基于任务计划(由总规划agent生成)的进度,给出正确的子任务规划和操作决策。
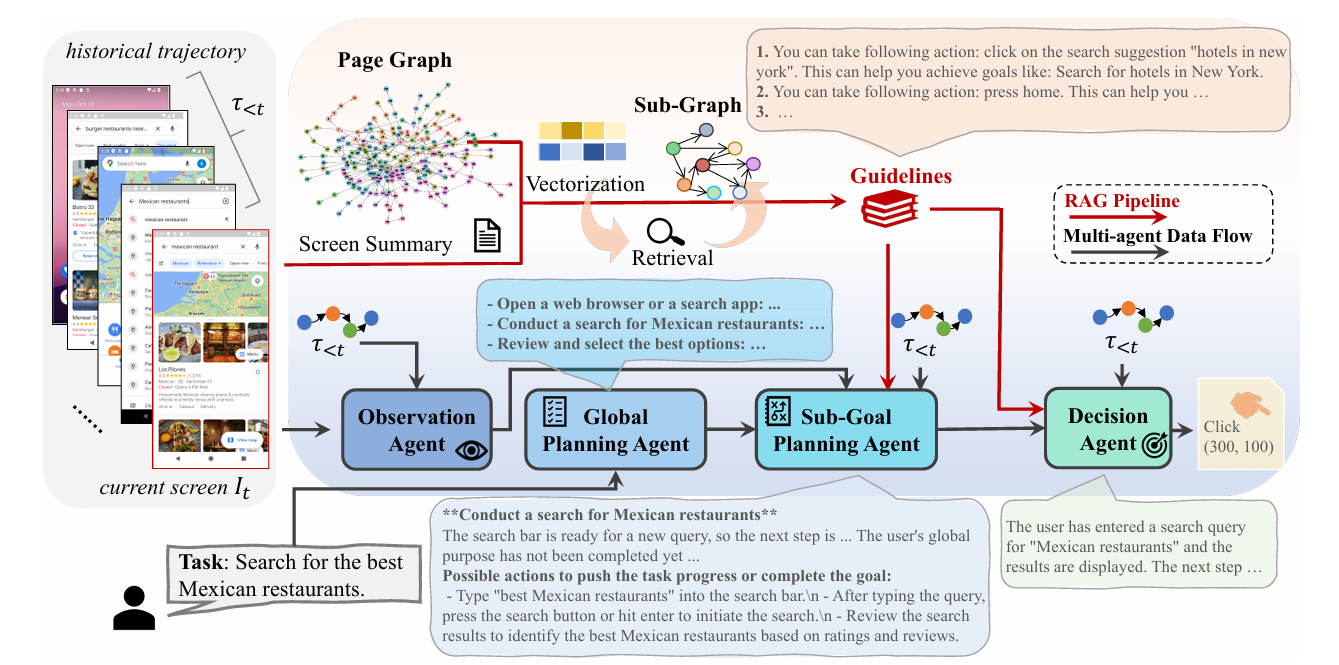
本研究通过在三个公开数据集上的测评,验证了在无需额外训练的情况下,页面图谱能够为agent提供准确的指导信息,从而提升执行任务时的准确率。
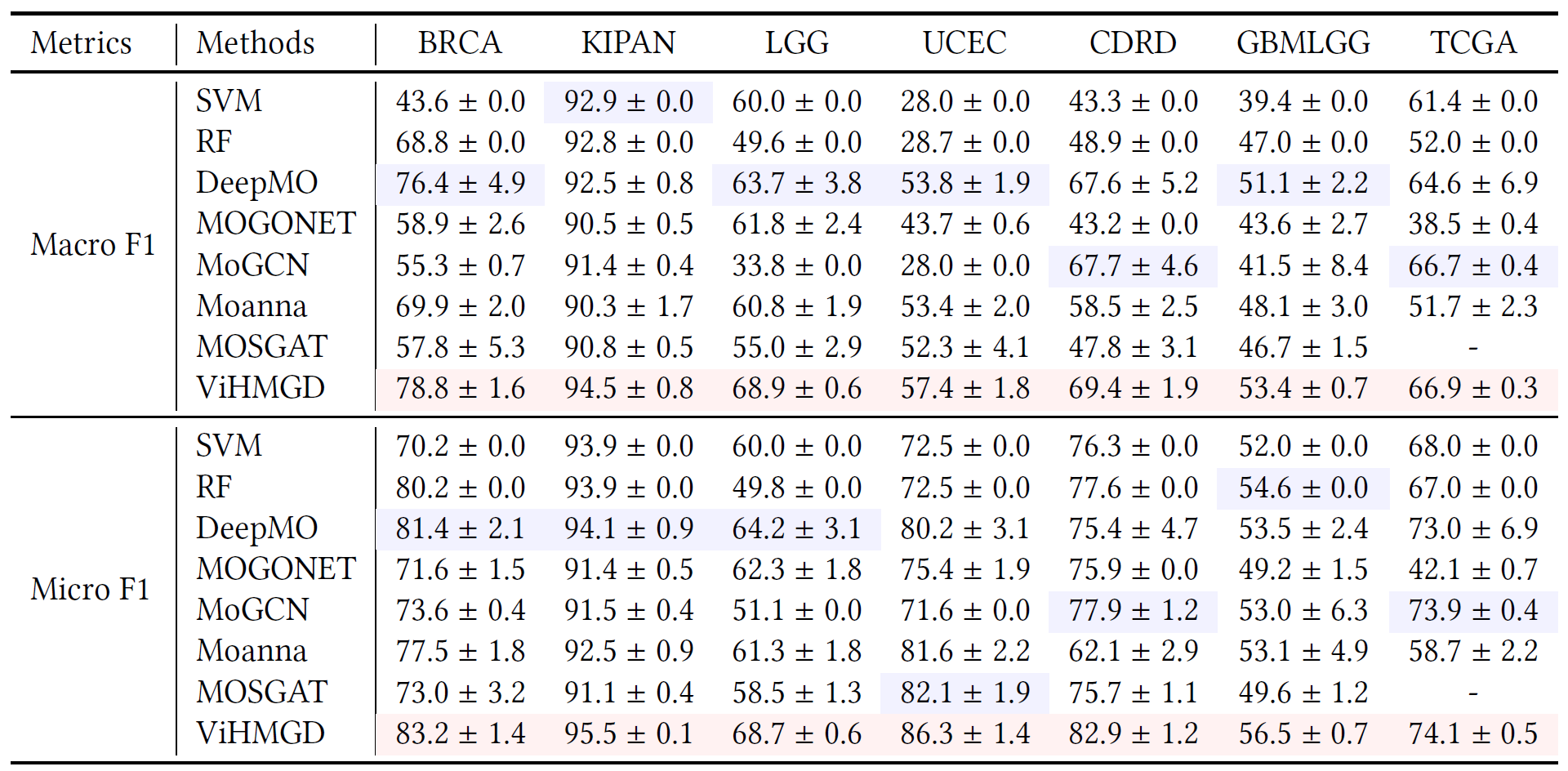
表1:Mind2Web
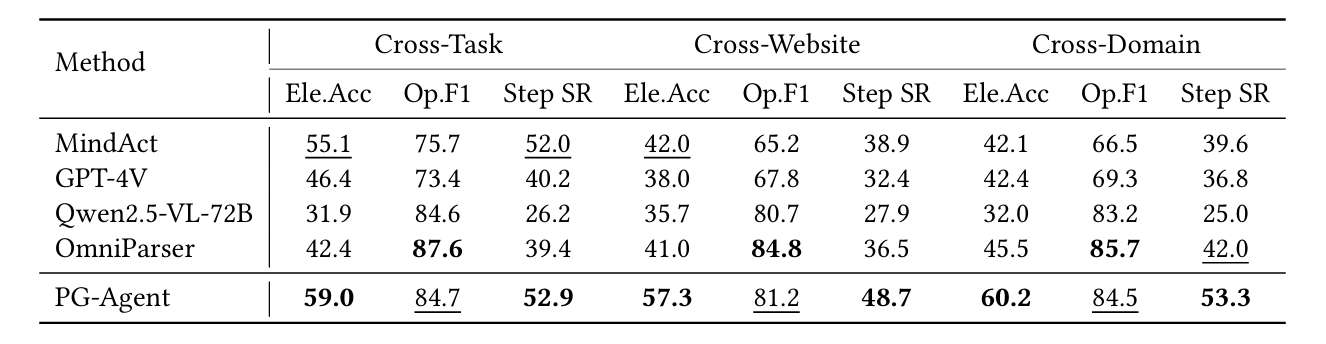
表2:GUIOdyssey
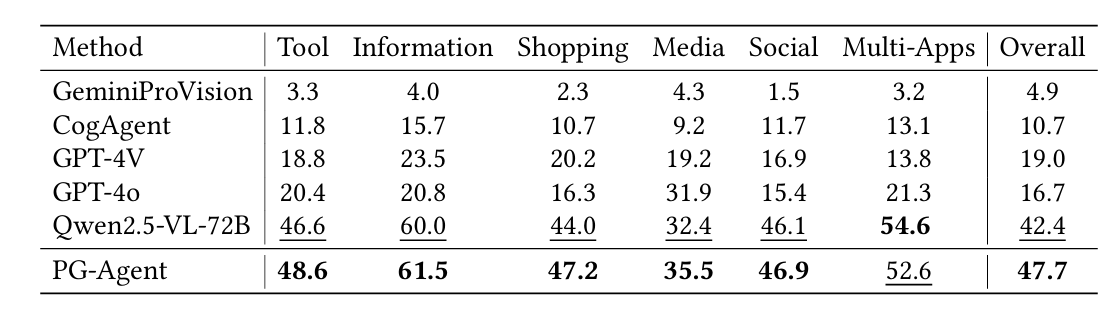
表3:AITW